2024.5.14比特币行情分析-模因币的牛市
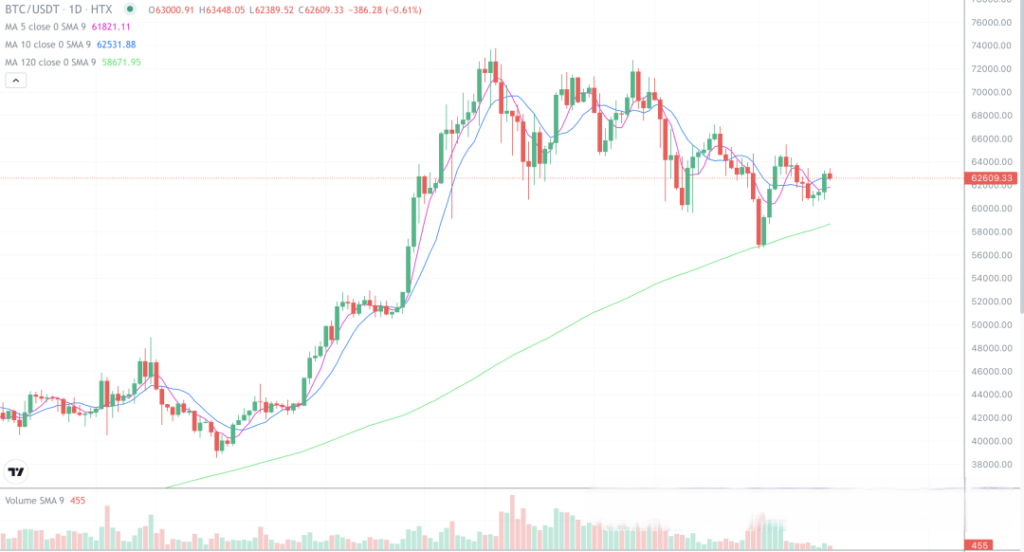
比特币目前的走势没有太大的变化,整体还是处于120日均线之上的调整行情,关键还是要看明天晚上老美的cpi数据,如果数据很好,短中期直接拉升,如果数据很垃圾,那么短中期就会下跌回调,会再次考验120日均线的支撑。这几天的市场过于冷清,唯有meme币扛起来大旗。
2024.5.14比特币行情分析-模因币的牛市 Read More »
比特币目前的走势没有太大的变化,整体还是处于120日均线之上的调整行情,关键还是要看明天晚上老美的cpi数据,如果数据很好,短中期直接拉升,如果数据很垃圾,那么短中期就会下跌回调,会再次考验120日均线的支撑。这几天的市场过于冷清,唯有meme币扛起来大旗。
2024.5.14比特币行情分析-模因币的牛市 Read More »
本期共近2500字,主要内容有:宏观情报,BTC盈亏比例,Uniswap,Coinbase,网络费用,看跌判断及批评,FUD USDT,ETF质押,ETF持仓总量,等。
2024.5.13币圈市场解读-90%的比特币地址盈利 Read More »
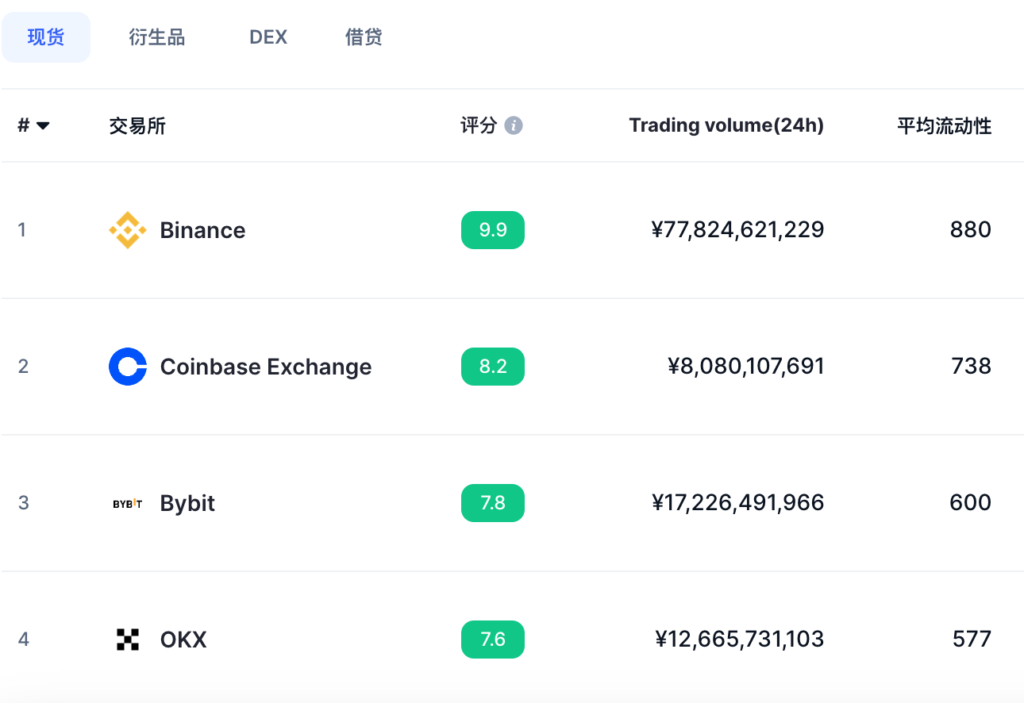
依据交易数据(成交量、市场深度、未平仓合约量)和合规信誉两个角度评估,世界五大比特币交易所是:币安、coinbase、欧易、bybit和uniswap。其中币安市场占有率50%以上,coinbase合规突出,欧易是中国老二,bybit合约突出,uniswap去中心化交易所老大。
全球比特币交易平台排行,世界五大比特币交易所 Read More »
比特币已经诞生10多年了,近3年从低位的3千-6千刀到如今的6万刀也涨了10倍起。
很多网友或是很年轻刚刚接触投资,或是陆续听过几次比特币但一直都没真正去行动,而现在终于开始着手接触比特币,就会关心“比特币到底怎么玩?怎么赚钱”。本文解答一下这个问题。
期现套利,顾名思义就是利用期货和现货的价差套利。期现套利的效果:“以比现货价格高5%-10%的价格直接卖掉比特币,但是套利过程需要3个月”。适合场外资金入场保本理财,或者场内闲置Usdt理财。
币圈资金费率套利的效果:
1、无风险,币本身涨跌与你无关;
2、纯吃利息,一天吃3次,一般年化在8%起,牛市年化在20%起。
适合人群:
想要做现金稳定理财的人。比如场外的钱想做点保本理财,或者场内的钱觉得现在币价高怕接盘,闲置usdt做个理财。
在频繁金融交易的过程中,如果今天挣1万,明天损失5000,那你就是一个非常成功的交易员,因为你是净赚的。可是即使这样非常成功的交易员,因为厌恶损失原理的存在导致你获得的快乐总是比失去的痛苦要稍微大一些。
所谓MEME币就是没有任何价值的空气币,比如在链上任意发行的一个代币,代币背后没有任何底层资产支持,也没有链上的任何开发项目。甚至一点掩饰都没有,只是明目张胆地传销。每一次币圈的牛市过程中,都会出现MEME现场。