



仅供自学使用。
For self-study only.
章节介绍
Introduction
* 第1章:awk基础入门
Chapter 1: Basic Introduction & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.1:awk简介
* 1.1: profiles of & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.2:学完awk你可以掌握:
* 1.2: You can handle: & nbsp; & nbsp; & nbsp; & nbsp;
* 1.3:awk环境简介
* 1.3:awk environmental profile & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.4:awk的格式
:: 1.4:awk format
* 1.5:模式动作
* 1.5: Mode Actions & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.6:awk的执行过程
:: 1.6: Awak implementation process
* 1.6.1:小结awk执行过程
* 1.6.1: Wrap-up awk implementation process
* 1.7:记录和字段
:: 1.7: Records and fields
* 1.7.1:记录(行)
* 1.7.1: Record (line) & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.7.2:记录分隔符-RS
* 1.7.2: Record separator - RS & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.7.3:对$0的认识
* 1.7.3: Awareness of $0 & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.7.4:企业面试题
:: 1.7.4: Enterprise interview issues
* 1.7.5:awk记录知识小结
:: 1.7.5: awk records the knowledge summing & nbsp;
* 1.7.6:字段(列)
* 1.7.6: Fields (column) & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.7.7:ORS与OFS简介
* 1.7.7: ORS and OFS profile & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 1.9:awk基础入门总结
:: 1.9:awak Basic Introduction Summary
* 第2章:awk进阶
:: Chapter 2: wk step & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.1:awk模式与动作
* 2.1:awk mode and actions
* 2.2:正则表达式作为模式
*2.2: Regular expression as mode
* 2.2.1:awk正则匹配操作符
* 2.2.1:awk regular matching operator & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.2.2:awk正则表达式匹配整行
* 2.2.2:awk regular expression matches the whole line
* 2.2.3:awk正则表达式匹配一行中的某一列
* 2.2.3:awk regular expression matches a column in a row & nbsp;
* 2.2.4:某个区域中的开头和结尾
* 2.2.4: The beginning and end of & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.2.5:创建测试环境
:: 2.2.5: Create a test environment
* 2.2.6:测试文件说明
:: 2.2.6: Test documentation description
* 2.2.7:awk正则表达式练习题
*2.2.7: awwk Regular Expression Practice & nbsp;
* 2.2.8:awk正则表达式练习题-详解
* 2.2.8:awk regular expression exercises - detailed & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.2.9:企业面试题
*2.2.9: Enterprise Interview & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.2.10:明明白白扩展正则表达式:+(加号)
*2.2.10: Clarity white extension regular expression: + (plus sign)
* 2.2.11:awk正则之{} -花括号
*2.2.11: {} - brackets & nbsp; & nbsp; & nbsp; & nbsp;
* 2.2.12:企业案例1
*2.2.12: Enterprise Case 1 & nbsp; & nbsp; & nbsp; & nbsp;
* 2.2.13:企业案例2
*2.2.13: Enterprise case 2 & nbsp; & nbsp; & nbsp; & nbsp;
* 2.3:比较表达式做为模式-需要一些例子
* 2.3: Comparative expression as model - some examples are needed
* 2.3.1:企业面试题
* 2.3.1: Enterprise interview & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.3.2:如果判断某一列是否等于某个字符呢?
* 2.3.2: What if a column is judged to be equal to a character? & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.4:范围模式
* 2.4: Scope mode & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.5:awk特殊模式-BEGIN模式与END模式
:: 2.5:awk special model -- BEGIN model and END model
* 2.5.1:BEGIN模块
* 2.5.1: BEGIN module & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.5.2:awk中变量的概念简介
* 2.5.2: Concept description of variables in awk & nbsp;
* 2.5.3:END模块
:: 2.5.3: END module
* 2.6:awk中的动作
* Action in 2.6:awk
* 2.7:awk模式与动作小结
:: 2.7:awk mode and motion summing up
* 2.8:总结awk执行过程
* 2.8: Summary of wk implementation & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.9:awk数组
* 2.9:awk array & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
* 2.10:图片-数组
* 2.10: Pictures - array & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp; & nbsp;
要弄懂awk程序,必须熟悉了解这个工具的规则。本实战笔记的目的是通过实际案例或面试题带同学们熟练掌握awk在企业中的用法,而不是awk程序的帮助手册。
The purpose of this manual is to provide students with a good grasp of how awk works in the business, rather than a help manual for the awk process.
- 一种名字怪异的语言
- 模式扫描和处理
awk不仅仅时linux系统中的一个命令,而且是一种编程语言,可以用来处理数据和生成报告(excel)。处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。本章主要讲解awk命令的运用。
Awak is not only an order in the time linux system, but also a programming language that can be used to process data and generate reports (excel). The data processed can be one or more documents, either from standard input, or from standard input via pipelines, which can be used directly to edit commands on the command line, or can be written into a wk program for more complex applications.
- 记录与字段
- 模式匹配:模式与动作
- 基本的awk执行过程
- awk常用内置变量(预定义变量)
- awk数组(工作常用)
- awk语法:循环,条件
- awk常用函数
- 向awk传递参数
- awk引用shell变量
- awk小程序及调试思路
- awk指令是由模式,动作,或者模式和动作的组合组成。
- 模式既pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如NR==1,这就是模式,可以把他理解为一个条件。
- 动作即action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开。比如awk使用格式:


awk处理的内容可以来自标准输入(<),一个或多个文本文件或管道。
The content processed by awk can be derived from standard input (<), one or more text files or conduits.
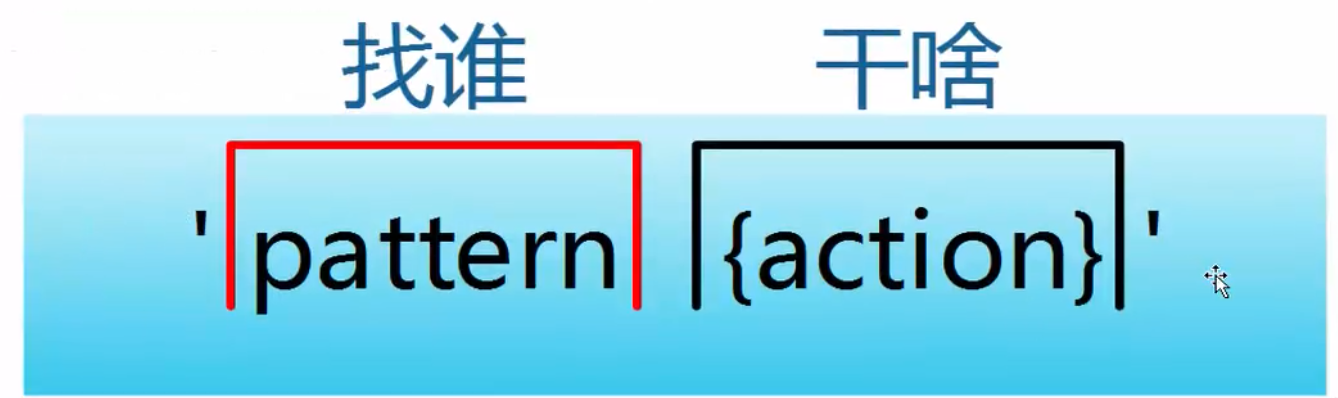

- pattern既模式,也可以理解为条件,也叫找谁,你找谁?高矮,胖瘦,男女?都是条件,既模式。
- action既动作,可以理解为干啥,找到人之后你要做什么。
模式和动作的详细介绍我们放在后面部分,现在大家先对awk结构有一个了解。
示例1-1: 基本的模式和动作
Example 1-1: Basic Modes and Actions
示例1-2 只有模式
示例1-3:只有动作
example 1-3: action only
示例1-4:多个模式和动作
example 1-4: multiple modes and actions
注意:
Note:
- Pattern和{Action}需要用单引号引起来,防止shell作解释。
- Pattern是可选的。如果不指定,awk将处理输入文件中的所有记录。如果指定一个模式,awk则只处理匹配指定的模式的记录。
- {Action}为awk命令,可以是但个命令,也可以多个命令。整个Action(包括里面的所有命令)都必须放在{ 和 }之间。
- Action必须被{ }包裹,没有被{ }包裹的就是Patern
- file要处理的目标文件
在深入了解awk前,我们需要知道awk如何处理文件的。
We need to know how the awk handles the documents before we get a deeper look at the awk.
示例1-5 示例文件的创建
Example 1-5 Creation of the Example File
这个文件仅包含十行文件,我们使用下面的命令:
This document contains only 10 rows of documents, and we use the following command:
示例1-6 awk执行过程演示
Example 1-6 awk executory process demonstration
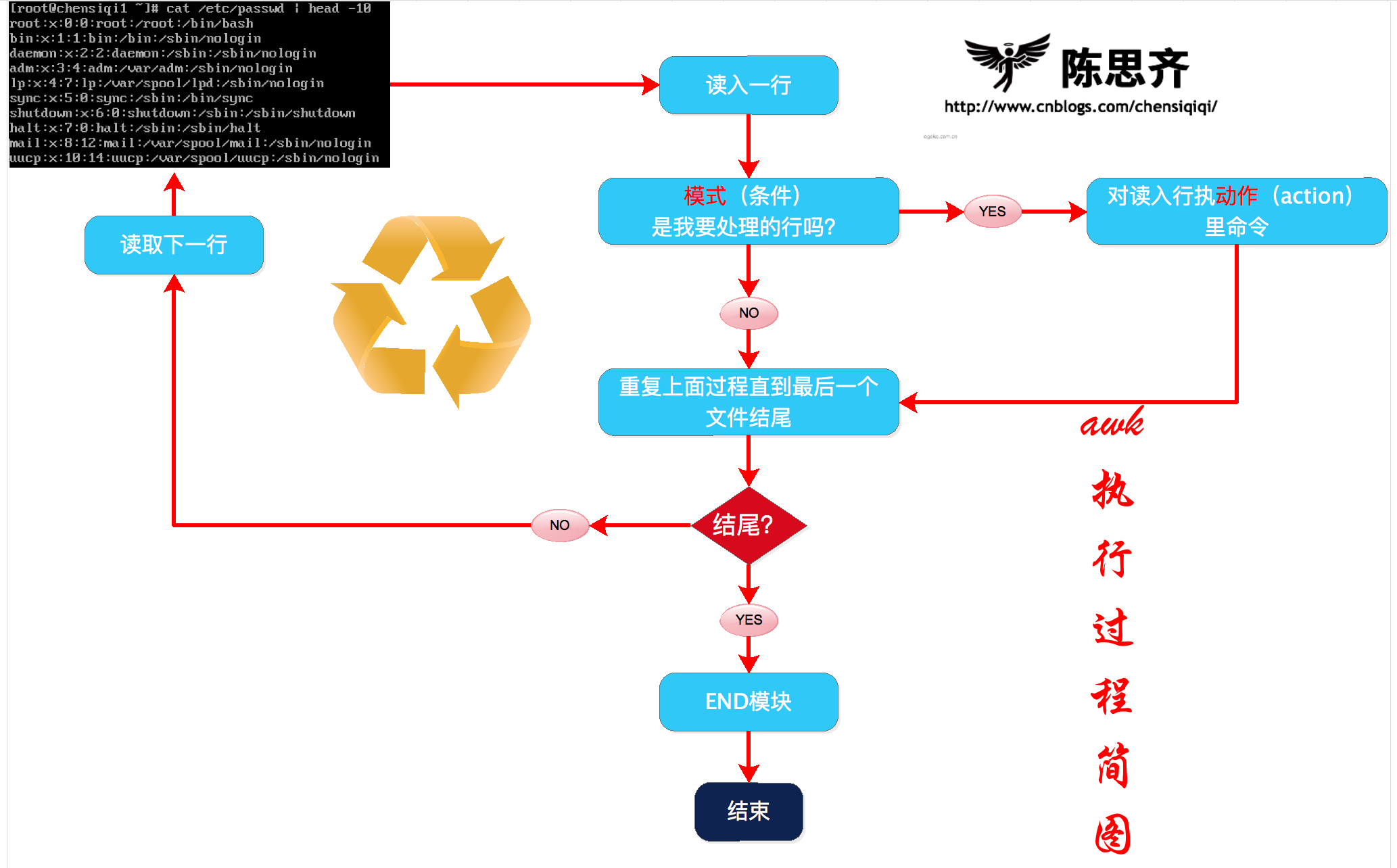
1.6.1 小结awk执行过程
1)awk读入第一行内容
1) awk read first line
2)判断是否符合模式中的条件NR>=2
2) NR>=2
a,如果匹配则执行对应的动作{print $0}
b,如果不匹配条件,继续读取下一行
a, perform the corresponding action {br>b if the match is matched; if the condition is not matched, continue reading the next line
3)继续读取下一行
4)重复过程1-3,直到读取到最后一行(EOF:end of file)
3) Continue reading the next line
4) repeat process 1-3 until you read the last line (EOF:end of file)

接下来我给大家带来两个新概念记录和字段,这里为了方便大家理解可以把记录就当作行即记录==行,字段相当于列,字段==列。
Next, I bring you two new concept records and fields, which, for the sake of ease of understanding, can be treated as lines, i.e. lines = rows, fields are equivalent to columns, fields = columns.
| 名称 | 含义 |
|---|---|
| record | 记录,行 |
| field | 域,区域,字段,列 |
1.7.1 记录(行)
查看一下下面这段文字
思考:
一共有多少行呢?你如何知道的?通过什么标志?
How many lines do you have? How do you know? By what sign?
awk对每个要处理的输入数据认为都是具有格式和结构的,而不仅仅是一堆字符串。默认情况下,每一行内容都是一条记录,并以换行符分隔( )结束
awk considers each input data to be processed to be formatted and structured, not just a bunch of strings. By default, each line is recorded and separated by line breaks ()
1.7.2 记录分隔符-RS


- awk默认情况下每一行都是一个记录(record)
- RS既record separator输入输出数据记录分隔符,每一行是怎么没的,表示每个记录输入的时候的分隔符,既行与行之间如何分隔。
- NR既number of record 记录(行)号,表示当前正在处理的记录(行)的号码。
- ORS既output record separator 输出记录分隔符。
awk使用内置变量RS来存放输入记录分隔符,RS表示的是输入的记录分隔符,这个值可以通过BEGIN模块重新定义修改。
Awk uses the built-in variable RS to store the input record separator, RS means the input record separator, a value that can be redefined through the BEGIN module.
示例1-1:使用“/”为默认记录分隔符
示例文件:
Example 1-1: Use "/" as default record separator
example file:
我们回顾下“行(记录)”到底是什么意思?
- 行(记录):默认以 (回车换行)结束。而这个行的结束不就是记录分隔符嘛。
- 所以在awk中,RS(记录分隔符)变量表示着行的结束符号(默认是回车换行)
在工作中,我们可以通过修改RS变量的值来决定行的结束标志,最终来决定“每行”的内容。
为了方便人们理解,awk默认就把RS的值设置为“
”
In our work, 注意: Note:
For ease of understanding, awl defaults to set the value of the RS to "
awk的BEGIN模块,我会在后面(模式-BEGIN模块)详细讲解,此处大家仅需要知道在BEGIN模块里面我们来定义一些awk内置变量即可。
awk, which I will explain in detail later (module-BEGIN module), all you need to know here is that in the BEGIN module we define some of the awk built-in variables.
1.7.3 对$0的认识
- 如1.7.2的例子,可以看出awk中$0表示整行,其实awk使用$0来表示整条记录。记录分隔符存在RS变量中,或者说每个记录以RS内置变量结束。
- 另外,awk对每一行的记录号都有一个内置变量NR来保存,每处理完一条记录,NR的值就会自动+1
- 下面通过示例来加深印象。
示例1-2:NR记录号
Example 1-2: NR log number
1.7.4 企业面试题:按单词出现频率降序排序(计算文件中每个单词的重复数量)
注:(此处使用sort与uniq即可)
Note: (Sort and uniq can be used here)
题目:
Subject:
题目创建方法:
Title Creation Method:
思路:
让所有单词排成一列,这样每个单词都是单独的一行
Put all words in one row, so that each word is a separate line.
1)设置RS值为空格
2)将文件里面的所有空格替换为回车换行符“
”
3)grep所有连续的字母,grep -o参数让他们排成一列。
1) Set RS value to space
2 to replace all spaces in a file with all consecutive letters of the line break "
3) grep-o parameters in a row.
方法一:
Method I:
方法二:
Option two:
方法三:
Option three:
1.7.5 awk记录知识小结
- NR存放着每个记录的号(行号)读取新行时候会自动+1
- RS是输入数据的记录的分隔符,简单理解就是可以指定每个记录的结尾标志。
- RS作用就是表示一个记录的结束
- 当我们修改了RS的值,最好配合NR(行)来查看变化,也就是修改了RS的值通过NR查看结果,调试awk程序。
- ORS输出数据的记录的分隔符
awk学习技巧一则:
大象放冰箱分几步?打开冰箱,把大象放进去,关闭冰箱门。
awk也是一样的,一步一步来,先修改了RS,然后用NR调试,看看到底如何分隔的。然后通过sort排序,uniq -c去重awk learning technique: How many steps does an elephant put in the fridge? Open the fridge, put the elephant in, close the door.
awk is the same, step by step, modify the RS, then use the NR to see how it is separated.
1.7.6 字段(列)
- 每条记录都是由多个区域(field)组成的,默认情况下区域之间的分隔符是由空格(即空格或制表符)来分隔,并且将分隔符记录在内置变量FS中,每行记录的区域数保存在awk的内置变量NF中。
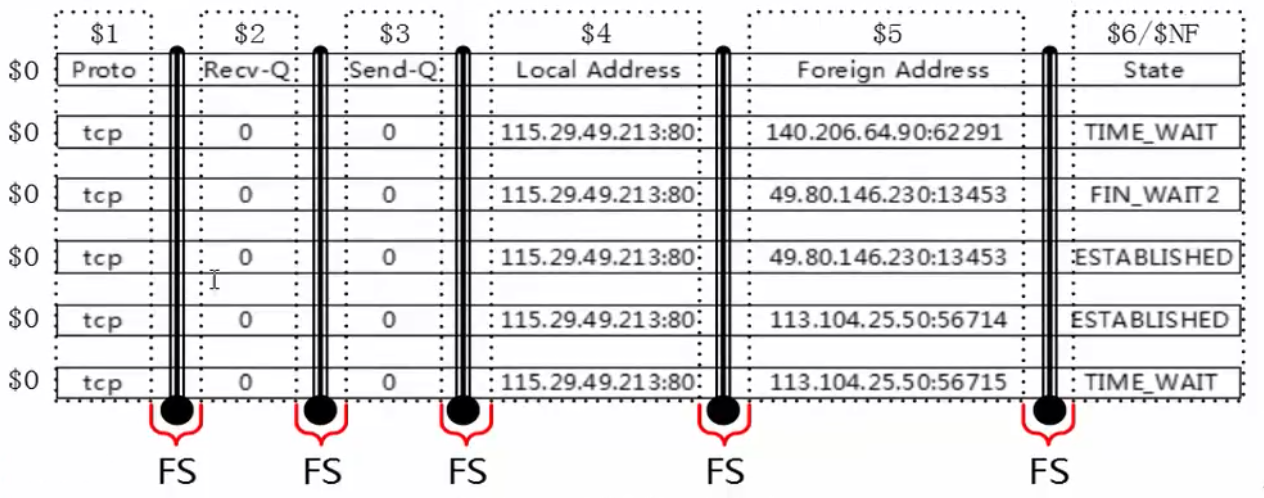

- FS既field separator,输入字段(列)分隔符。分隔符就是菜刀,把一行字符串切为很多个区域。
- NF既number of fileds,表示一行中列(字段)的个数,可以理解为菜刀切过一行后,切成了多少份。
OFS输出字段(列)分隔符
ofS output field (column) separator
- awk使用内置变量FS来记录区域分隔符的内容,FS可以在命令行上通过-F参数来更改,也可以通过BEGIN模块来更改。
- 然后通过$n,n是整数,来取被切割后的区域,$1取第一个区域,$2取第二个区域,$NF取最后一个区域。
下面我们通过示例来加强学习。
Here's an example of how we can strengthen learning.
示例1-3:指定分隔符
Example 1-3: Specify separator
- 此处的FS知识一个字符,其实它可以指定多个的,此时FS指定的值可以是一个正则表达式。
- 正常情况下,当你指定分隔符(非空格)的时候,例如指定多个区域分隔符,每个分隔符就是一把刀,把左右两边切为两个部分。
企业面试题:同时取出chensiqi和215379068这两个内容(指定多分隔符)
Enterprise interview question: removes both Chensiqi and 215379068 (assign multiple separator)
同时取出chensiqi和1234567890这两个内容。
Both Chensiqi and 1234567890 were removed.
思路:
我们用默认的想法一次使用一把刀,需要配合管道的。如何同时使用两把刀呢?看下面的结果
We use a knife at a time with the default idea and we need to work with the pipe. How do we use two knives at a time? Look at the results below.
小技巧:
在动作(‘{print $3,$NF}’)里面的逗号,表示空格,其实动作中的逗号就是OFS的值,我们会在后面说明。刚开始大家把动作中的都逗号,当作空格即可。:
comma in action (`print $3, $NF}) means space, but the comma in action is the value of OFS, which we will explain later. At the outset, everyone will use comma in action as a space.
示例:默认分隔符和指定分隔符会有些差异
Example: The default separator and the specified separator will differ
- 这个文件的开头有很多连续的空格,然后才是inet这个字符
- 当我们使用默认的分隔符的时候,$1是有内容的。
- 当我们指定其他分隔符(非空格)时候,区域会有所变化
- 到底为何会这样,我们在这里不再深入研究,只要了解有这种情况,注意一下即可。
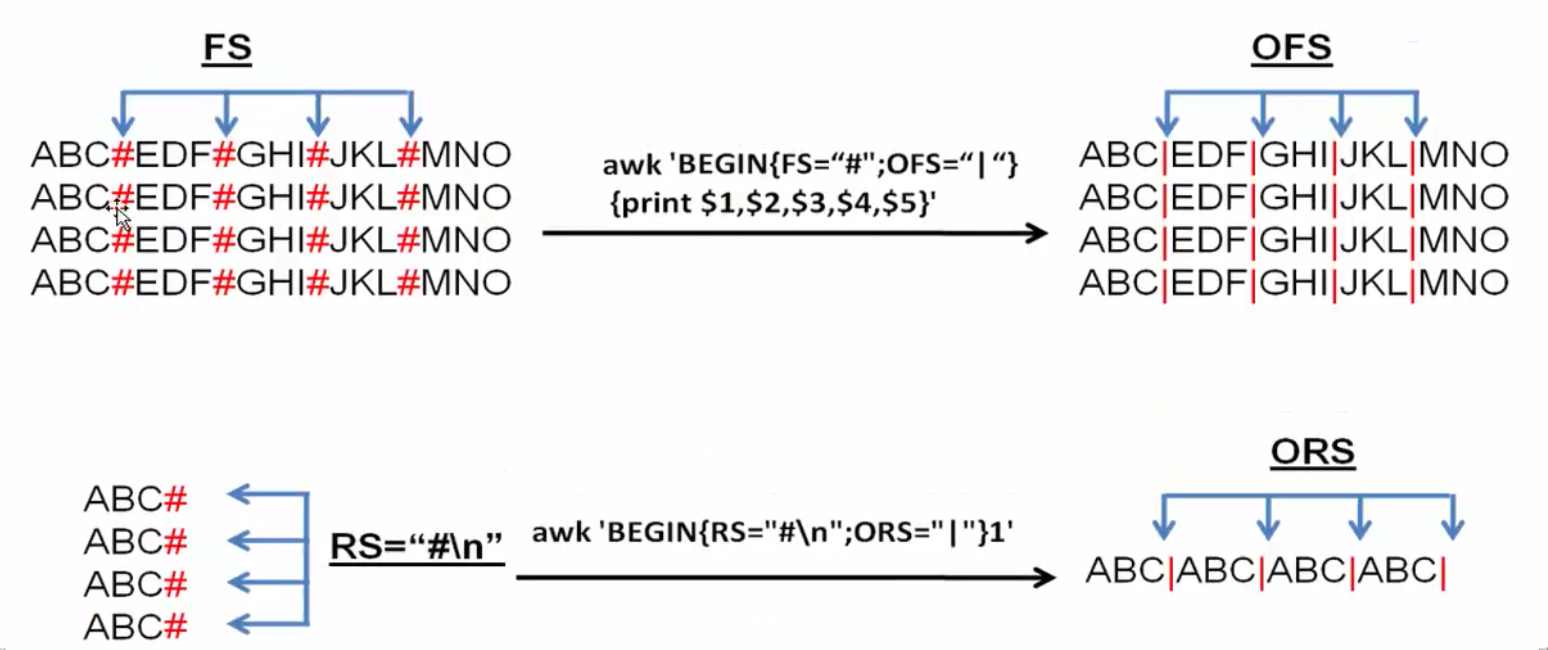
1.7.7 ORS与OFS简介
现在说说ORS和OFS这两个内置变量的含义。
Now let's talk about the meaning of the two built-in variables, ORS and OFS.
- RS是输入记录分隔符,决定awk如何读取或分隔每行(记录)
- ORS表示输出记录分隔符,决定awk如何输出一行(记录)的,默认是回车换行( )
- FS是输入区域分隔符,决定awk读入一行后如何再分为多个区域。
- OFS表示输出区域分隔符,决定awk输出每个区域的时候使用什么分隔她们。
- awk无比强大,你可以通过RS,FS决定awk如何读取数据。你也可以通过修改ORS,OFS的值指定awk如何输出数据。

现在你应该会对awk的记录字段有所了解了,下面我们总结一下,学会给阶段性知识总结是学好运维的必备技能。
Now you're going to learn about the ack record field, and let's take a look at it. Learning to synthesize a stage of knowledge is a necessary skill for learning about good luck.


- RS记录分隔符,表示每行的结束标志
- NR行号(记录号)
- FS字段分隔符,每列的分隔标志或结束标志
- NF就是每行有多少列,每个记录中字段的数量
- NF表示记录中的区域(列)数量,取最后一个列(区域。)
- FS(-F)字段(列)分隔符,-F(FS)“:”<==>‘BEGIN{FS=':'}’
- RS 记录分隔符(行的结束标识)
- NR 行号
- 选好合适的刀FS(***),RS,OFS,ORS
- 分隔符==>结束标识
- 记录与区域,你就对我们所谓的行与列,有了新的认识(RS,FS)
到了这里我们回头看看,我们之前学习的内容。
When we get here, we look back at what we learned earlier.
- awk的命令行结构
- awk的模式和动作
- awk的记录和字段
比较核心常用的是字段。
另外这些企业面试题可是学会awk的必备,必须自己也能写出来。
What's more common at the core is the field.
These corporate interview topics are essential for learning awl and must be self-written.
接下来就详细介绍下,awk的模式都有几种:
For further details, there are several models for awk:
- 正则表达式作为模式
- 比较表达式作为模式
- 范围模式
- 特殊模式BEGIN和END
awk的模式是你玩好awk的必备也是最基础的内容,必须熟练掌握
The pattern of awk同sed一样也可以通过模式匹配来对输入的文本进行匹配处理。说到模式匹配,肯定少不了正则表达式,awk也支持大量的正则表达式模式,大部分与sed支持的元字符类似,而且正则表达式是玩转三剑客的必备工具,下表列出了awk支持的正则表达式元字符: Awak, like sed, can match the text entered by matching the mode. Speaking of pattern matching, there must be a lot of regular expressions, ack also supports a lot of regular expressions, most of which are similar to the characters supported by sed, and regular expressions are essential tools to play with the three Musketeers, and the regular expression characters supported by awk are listed in the table below: awk默认就支持的元字符: awk defaultly supports the character: awk默认不支持的元字符:(参数--posix) awk default unsupported meta characters: (parameter -- posix) 提示: hint: awk正则匹配操作符: awl matching operator: 下面还是通过具体示例来看看,awk如何来通过正则表达式匹配字符串的 Let's go over here with a concrete example of how awl matches a string with a regular expression. 和下面的效果是一样的 and the effect below is the same 提示: hint: awk只用正则表达式的时候是默认匹配整行的即‘$0~/^root/’和‘/^root/’是一样的。 When only regular expressions are used, the default matches the entire line with the same `$0~/root/' and root/'. 提示: hint: 合并在一起 $5~/shutdown/表示第五个区域(列)匹配正则表达式/shutdown/,既第5列包含shutdown这个字符串,则显示这一行。 $5~/shutdown/ represents the fifth area (column) matching regular expression/shutdown/, and this line is shown when column 5 contains the string shutdown. 知道了如何使用正则表达式匹配操作符之后,我们来看看awk正则与grep和sed不同的地方。 When we know how to use regular expression matching operators, let's see where awl is different from grep and sed. awk正则表达式 在sed和grep这两个命令中,我们都把它们当作行的开头和结尾。但是在awk中他表示的是字符串的开头和结尾。 In both the sed and grep commands, we all treat them as the beginning and end of a line. But in awl he says the beginning and end of a string. 接下来我们通过练习题来联系awk如何使用正则表达式。 Next we're going to practice the theme of how awk uses regular expressions. 说明: Note: 练习题1:显示姓Zhang的人的第二次捐款金额及她的名字 Practice question 1: Show the second donation of a man named Zhang and her name. 练习题2:显示Xiaoyu的名字和ID号码 Practice No. 2: Show Xiaoyu's name and ID number 练习题3:显示所有以41开头的ID号码的人的全名和ID号码 Practice No. 3: Show full name and ID number of all IDs starting with 41. 练习题4:显示所有以一个D或X开头的人名全名 Practice Question 4: Show all names starting with one D or X 练习题5:显示所有ID号码最后一位数字是1或5的人的全名 Practice Question 5: Show the full name of the person whose last ID number is 1 or 5. 练习题6:显示Xiaoyu的捐款,每个值都有以$开头。如$520$200$135 Practice Question 6: Shows a contribution from Xiaoyu, each value starts with a dollar. For example, $520,200 $135 练习题7:显示所有人的全名,以姓,名的格式显示,如Meng,Feixue Practice question 7: display the full name of all persons, in the form of surnames and names, such as Meng, Feixue 示例1:显示姓Zhang的人的第二次捐款金额及她的名字 Example 1: Show the second contribution of a person named Zhang and her name 说明: Note: 注意: 示例2:显示Xiaoyu的姓氏和ID号码 Example 2: Show Xiaoyu's last name and ID number 示例3:显示所有以41开头的ID号码的人的全名和ID号码 Example 3: Show full name and ID number of all IDs starting with 41. 示例4:显示所有以一个D或X开头的人名全名 Example 4: Show all names starting with one D or X 注意: Note: 示例5:显示所有ID号码最后一位数字是1或5的人的全名 Example 5: Full name of the person indicating that the last number of all ID numbers is one or five 示例6:显示Xiaoyu的捐款,每个值都有以$开头。 Example 6: Show the contribution of Xiaoyu with each value starting with $. 示例7:显示所有人的全名,以姓,名的格式显示,如Meng,Feixue Example 7: display the full name of all persons, in the form of surnames and names, such as Meng, Feixue 最简单:hostname -I Simplest: hostname-I awk处理: awl: 方法一: Method I: 方法二: Option two: 方法三: Option three: 方法四: Option four: 提示: hint: 注意: Note: awk中的花括号有些不常用,但是偶尔会用到这里简单介绍。 Some of the brackets in awk are not commonly used, but are sometimes used here for brief introductions. 示例:取出awkfile中第一列包含一个o或者两个o的行 Example : removes the first row in awlfile containing one or two rows of o 思路: Ideas: The corresponding tables for service and port information below 我们简单分析以下servics文件: We briefly analyse the following servics documents: 从23行开始基本上每一行第一列是服务名称,第二列的第一部分是端口号,第二列的第二部分是tcp或udp协议。 From line 23, the first column of each row is the service name, the first part of the second column is the port number, and the second part of the second column is the tcp or udp agreement. 方法: Methodology: 提示: Hint: 同学们自己尝试下 Let's try it on our own. 之前我们看了正则表达式在awk下的运用,下面再具体看看比较表达式如何在awk下工作。 Before we looked at the use of regular expressions under awl, we went on to see how comparative expressions worked under awl. awk是一种编程语言,能够进行更为复杂的判断,当条件为真时候,awk就执行相关的action。主要是针对某一区域做出相关的判断,比如打印成绩在80分以上的行,这样就必须对这一区域做比较判断,下表列出了awk可以使用的关系运算符,可以用来比较数字字符串,还有正则表达式。当表达式为真时候,表达式结果1,否0,只有表达式为真,awk才执行相关的action Awk is a programming language that allows for more complex judgements, and when the conditions are true, awk executes the relevant action. The relevant judgement is made mainly for a region, such as a row with a print score of 80 or more, so that a comparative judgement must be made on the area. The table below lists the relationship operators that awk can use, which can be used to compare numerical strings and regular expressions. When the expression is true, the expression results 1, 0, and only the expression is true, awk executes the relevant action. 以上运算符是针对数字的,下面两个运算符之前已有示例,针对字符串 The above operator is for numbers. The following two operators have examples before, for string 思路: 答案: Answer: 过程: Process: 说明: Note: 示例:找出/etc/passwd中第五列是root的行 Example: Find/etc/passwd where the fifth column is root's row 测试文件: Test file: 答案: Answer: 过程: Process: 我们如果想要完全匹配root这个字符串,那就用即可,这也是答案里面给大家的。 If we want to match exactly the root string, we can use it, and that's what's in the answer for you. 方法二: Method II: 1)还记得sed使用地址范围来处理文本内容嘛?awk的范围模式,与sed类似,但是又有不同,awk不能直接使用行号来作为范围起始地址,因为awk具有内置变量NR来存储记录号,所有需要使用NR=1,NR=5这样来使用。 范围模式的时候,范围条件的时候,表达式必须能匹配一行。 The expression must match a line at the time of the range mode and at the time of the range condition. 示例1: Example 1: 说明: Note: 示例2: Example 2: 说明: Note: 示例3: Example 3: 说明: Note: 说明: Description: 1)第一个作用,内置变量的定义 1) The first role, definition of built-in variables 示例:取eth0的IP地址 Example: take an IP address for eth0 答案: Answer: 注意: Note: 2)第二个作用,在读取文件之前,输出些提示性信息(表头)。 2) Second function, to produce indicative information (table header) before reading a file. 说明: Note: 3)第三个作用,使用BEGIN模块的特殊性质,进行一些测试。 3) Third function, some tests are conducted using the special nature of the BEGIN module. 4)第四种用法:配合getline读取文件,后面awk函数处讲解 4) Fourth usage: read files in conjunction with getline, followed by awk function 说明: Note: EHD在awk读取完所有的文件的时候,再执行END模块,一般用来输出一个结果(累加,数组结果),也可以是和BEGIN模块类似的结尾标识信息 EHD executes END modules when all files are read in awk, usually for the output of one result (cumulative, array of results), or for end-indent information similar to the BEGIN module 与BEGIN模式相对应的END模式,格式一样,但是END模式仅在awk处理完所有输入行后才进行处理。 The EEND mode, which corresponds to the BEGIN mode, is the same format, but EEND mode is processed only after awk has processed all input lines. 企业案例:统计/etc/servies文件里的空行数量 Business case: number of empty rows in statistics/etc/services files 思路: Ideas: 方法一:grep Method I: grep 方法二: Option two: 提示: Nintendo: 我们可以通过来查看awk执行过程 We can look at the ack execution by looking at it. 第二步:输出最后结果 Step 2: Output of final results 所以最终结果就是 So the end result is... awk编程思想: awk programming thought: 企业面试题5:文件count.txt,文件内容是1到100(由seq 100生成),请计算文件每行值加起来的结果(计算1+...+100) 思路: Ideas: Each line of the 对比一下,其实只是把上边的1换成了$0 Compared to "strange", it's just the top one for $0. 在一个模式-动作语句中,模式决定动作什么时候执行,有时候动作会非常简单:一条单独的打印或赋值语句。在有些时候,动作有可能是多条语句,语句之间用换行符或分号分开。 In a mode-action statement, the mode determines when the action will be carried out, and sometimes the action will be very simple: a separate print or value statement. In some cases, the action may be multiple statements, separated by line breaks or semicolons. In two or more words in the action of 回顾一下awk的结构 Look at the structure of the ack. awk -F 指定分隔符 ‘BRGIN{}END{}’,如下图 Awl-F specifies the separator `BRGINEND{}, as follows: 说明: Note: awk提供了数组来存放一组相关的值。 Awk provides arrays to store a related set of values. 如图不难发现,awk数组就和酒店一样。数组的名称就像是酒店名称,数组元素名称就像酒店房间号码,每个数组元素里面的内容就像是酒店房间里面的人。 If you can see it, the ack array is the same as the hotel. The name of the array is like the hotel name, the name of the array element is like the hotel room number, and the contents of each array of elements are like the person in the hotel room. 假设我们有一个酒店 Let's say we have a hotel. 酒店里面有几个房间110,119,120,114这几个房间 There's a few rooms in the hotel. 110, 119, 120, 114. 酒店房间里面入住客人 We've got guests in the hotel room. 示例: Example: 企业面试题1:统计域名访问次数 Enterprise interview question 1: Number of statistical domain name visits 处理以下文件内容,将域名取出并根据域名进行计数排序处理:(百度和sohu面试题) Process the following file contents, remove domain names and process them in numerical order: (100 degrees and sohu interview questions) 思路: Ideas: 过程演示: process demonstration: First step: look at the content 第二步:计数 Step 2: Counting 第三步:用数组替换i Step 3: Replace i with arrays 第四步:输出最终计数结果 Step 4: Output of final count results 提示: reminder: The most important function in the application of br>awk is counting, while the greatest function of arrays in awl is to repeat it. Please understand carefully and try more.
元字符 功能 示例 解释
^
字符串开头
/^chensiqi/或$3~/^chensiqi/
匹配所有以chensiqi开头的字符串;匹配出所有第三列中以chensiqi开头的
$
字符串结尾
/chensiqi$/或$3~/chensiqi$/
匹配所有以chensiqi结尾的字符串;匹配第三列中以chensiqi结尾的
.(点)
匹配任意但个字符(包括回车符)
/c..l/
匹配字母c,然后两个任意字符,再以l结尾的行
*
重复0个或多个前一个字符
/a*cool/
匹配0个或多个a之后紧跟着cool的行
+
重复前一个字符一次或多次
/a+b/
匹配一个或多个a加上字符串b的行
?
匹配0个或一个前边的字符
/a?b/
匹配以字母a或b或c开头的行
[]
匹配指定字符组内的任一个字符
/^[abc]/
匹配以字母a或b或c开头的行
[^]
匹配不在指定字符组内的任一字符
/^[^abc]/
匹配不以字母a或b或c开头的行
()
子表达式组合
/(chensiqi)+/
表示一个或多个cool组合,当有一些字符需要组合时,使用括号括起来
或者的意思
匹配chensiqi或字母B的行
元字符 功能 示例 解释
x{m}
x字符重复m次
/cool{5}/
匹配l字符5次
x{m,}
x字符重复至少m次
/(cool){2,}/
匹配cool整体,至少2次
x{m,n}
x字符重复至少m次,但不超过n次
/(cool){5,6}/
匹配cool整体,至少5次,最多6次
2.2.1 awk正则匹配操作符
|~|用于对记录或区域的表达式进行匹配|
|--|--|
|!~|用于表达与~相反的意思|
the2.2.2 awk正则表达式匹配整行
2.2.3 awk正则表达式匹配一行中的某一列
2.2.4 某个区域中的开头和结尾
|^|匹配一个字符串的开头|
|--|--|
|$|匹配一个字符串的结尾|2.2.5 创建测试环境
2.2.6 测试文件说明
2.2.7 awk正则表达式练习题
2.2.8 awk正则表达式练习题-详解
NF是一行中有多少列,NF-1整行就是倒数第二列。
$(NF-1)就是取倒数第二列内容。
NF is the number of columns in a row, and NF-1 as a whole is the second last column.
$(NF-1) is the second last column.
这里要用()括号表示即^(D|X)相当于^D|^X,有的同学写成^D|X这样是错误的。
This is expressed in brackets, i.e. DX, which is equivalent to DX. Some of the classmates were wrong to write DX.2.2.9 企业面试题:取出网卡eth0的ip地址
正则表达式是玩好awk的必要条件,必会掌握
regular expressions are essential to play awl and must be mastered2.2.10 明明白白扩展正则表达式:+(加号)
2.2.11 awk正则之{} -花括号
2.2.12 企业案例1:取出常用服务端口号
linux下面服务与端口信息的对应表格在/etc/services里面,所以这道题要处理/etc/services文件。
linux are in /etc/services, so this issue is dealt with in /etc/services files.
2.2.13 企业案例2:取出常用服务端名称
运算符 含义 示例
<
小于
x>y
<=
小于等于
x<=y
==
等于
x==y
!=
不等于
x!=y
>=
大于或等于
x>=y
>
大于
x<y
~ 与正则表达式匹配 x~/y/
!~
与正则表达式不匹配
x!~y
2.3.1 企业面试题:取出文件/etc/services的23~30行
想表示一个范围,一个行的范围,就要用到NR这个内置变量了,同时也要用到比较表达式。
wants to indicate a range, a line range, to use the NR as a built-in variable and also to use a comparative expression.
1)比较表达式比较常用的还是表示大于等于,小于等于或者等于,根据这个例子来学习即可
2)NR表示行号,大于等于23即,NR>=23小于等于30,即NR<=30
3)合起来就是NR>=23并且NR<=30,&&表示并且,同时成立的意思。
4)换一种表达式方法就是大于22行小于31行,即NR>22&&NR<31
1) Whether a comparative expression is more commonly expressed than equal to, and less than or equal to,
2) NR indicates a line number greater than or equal to 23, NR> = 23 is or less than 30, NR> = 23 and NR< = 30, & & & & &, meaning both.
4) Replace an expression method is or greater than 22 lines less than 31, NR> 22 & NR& lt; 31;2.3.2 如果判断某一列是否等于某个字符呢?
此题也可通过正则匹配来限制root的字符串。
may also limit the string of root by regular matching.
pattern1 pattern2
从哪里来
到
哪里去
条件1
条件2
2)范围模式处理的原则是:先匹配从第一个模式的首次出现到第二个模式的首次出现之间的内容,执行action。然后匹配从第一个模式的下一次出现到第二个模式的下一次出现,直到文本结束。如果匹配到第一个模式而没有匹配到第二个模式,则awk处理从第一个模式开始直到文本结束全部的行。如果第一个模式不匹配,就算第二个模式匹配,awk依旧不处理任何行。
条件是:从第二行,到第五行
动作是:显示行号(NR)和整行($0)
合起来就是显示第二行到第五行的行好和整行的内容
condition: From the second line to the fifth line
action is to show the line number (NR) and the whole line ($0
条件是:从以bin开头的行,到第五行
动作是:显示行号和整行内容
合起来就是显示从以bin开头的行,到第五行中的行号和整行内容。
条件:从第五列以bin开头的行到以lp开头的行
动作:显示行号和正航内容
合起来:从第三列以bin开始的行到以lp开头的行并显示其行号和整行内容
Condition: From row beginning with bin in column 5 to line
action starting with rp: Show line numbers and regular content
combined: From row starting with bin in column 3 to row starting with rp and displaying its line number and whole content
条件:从第三列以bin开头字符串的行到第三列以lp开头字符串的行
动作:显示行号和整行
Condition: Line
action from row with bin at the beginning of column 3 to line
action with rp with rp at the beginning of column 3: display line numbers and whole rows
2.5.1 BEGIN模块
命令行-F本质就是修改的FS变量
Command Line-F is a modified FS variable
要在第一行输出一些username和UID,我们应该想到BEGIN{}这个特殊的条件(模式),因为BEGIN{}在awk读取文件之前执行的。
所以结果是,注意print命令里面双引号吃啥吐啥,原样输出。
然后我们实现了在输出文件内容之前输出“username”和“UID”,下一步输出文件的第一列和第三列即
最后结果就是
to export some usernames and UIDs in the first line, we should think of BEGIN{} as a special condition (mode) because BEGIN{} executed before awk reads the file. 2.5.2 awk中变量的概念简介
没有文件awk依旧可以处理BEGIN模式下的动作(命令)
No file awk can still handle actions in BEGIN mode (command)2.5.3 END模块
a)空行通过正则表达式来实现:^$
b)统计数量:
a) Empty rows achieve by regular expression: br>b) Statistics:
使用了awk的技术功能,很常用
第一步:统计空行个数
表示条件,匹配出空行,然后执行{i++}(i++等于i=i+1)即:
uses awk's technical functionality, and often uses
文件每一行都有且只有一个数字,所以我们要让文件的每行内容相加。
回顾一下上一道题我们用的是i++即i=i+1
这里我们需要使用到第二个常用的表达式
i=i+$0
document has only one number, so we want to add each line of the document.
awk的动作中如果有两个或两个以上的语句,需要用分号分隔
动作部分大家理解为花括号里面的内容即可,总体分为:
awk, a semicolon is needed to separate the parts of the action of
1)正则表达式:必须掌握正则,熟练
2)条件表达式:比大小,比较是否相等
3)范围表达式:从哪里来到哪里去
我们·同时再命令行定义了分隔符和在BEGIN模式中定义了RS内置变量,在最后通过END模式输出了结果
We. also command lines define separator and RS built-in variables in the BEGIN mode, and end up exporting results through END mode
awk是一种编程语言,肯定也支持数组的运用,但是又不同于c语言的数组。数组在awk中被称为关联数组,因为它的下标既可以是数字也可以是字符串。下标通常被称作key,并且与对应的数组元素的值关联。数组元素的key和值都存储在awk程序内部的一张表中,通过一定散列算法来存储,所以数组元素都不是按顺序存储的。打印出来的顺序也肯定不是按照一定的顺序,但是我们可以通过管道来对所需的数据再次操作来达到自己的效果。
awk is a programming language and certainly supports the use of arrays, but it is different from the arrays in the c language. The arrays are called association arrays in the awk because their subscripts can be either numbers or strings. The subscripts are usually referred to as key, and are associated with the values of the corresponding array elements. The key and the values of the array elements are stored in a table inside the awk program and are stored through a certain hash algorithm, so the group elements are not stored sequentially. The order in which they are printed is certainly not in a given order, but we can use the pipe to reoperate the required data to achieve our effects.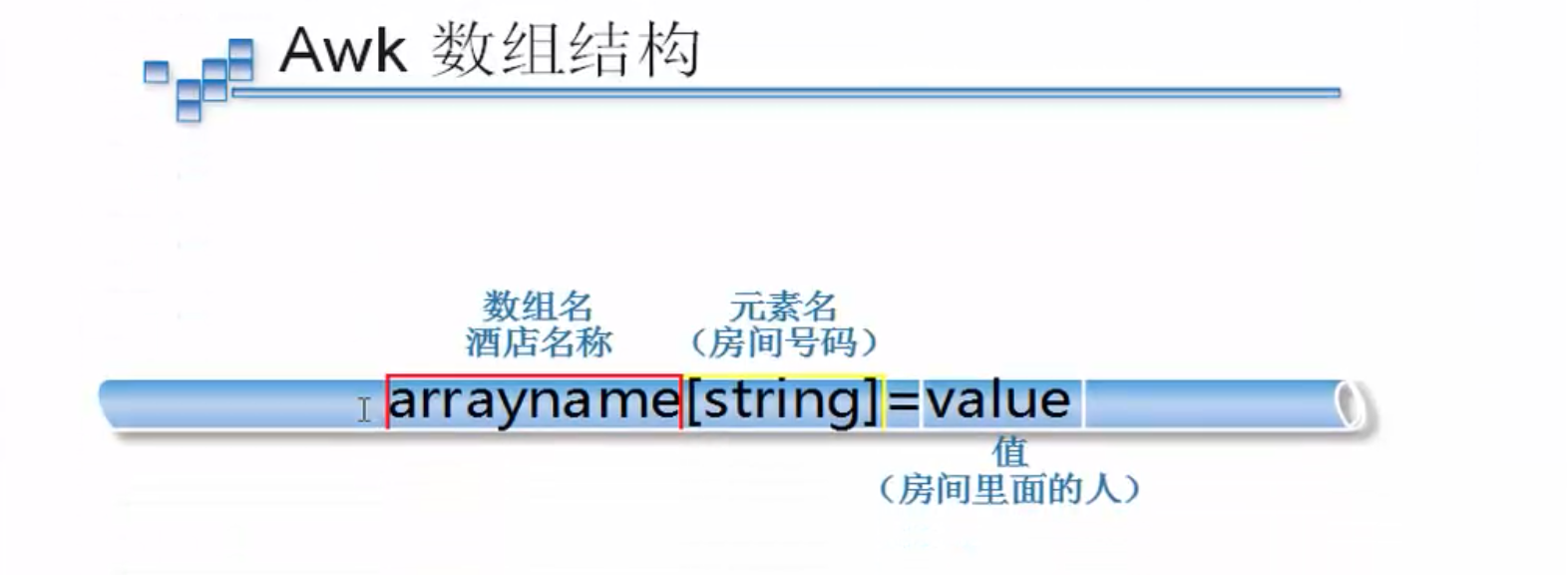

1)以斜线为菜刀取出第二列(域名)
2)创建一个数组
3)把第二列(域名)作为数组的下标
4)通过类似于i++的形式进行计数
5)统计后把结果输出
1) takes the second column (domain name)
2 and creates an array
3 and uses the second column (domain name) as the subscript for the array
4 and returns the results by counting
5 in a form similar to i++
第一步:查看一下内容
awk的应用里最重要的一个功能就是计数,而数组在awk里最大的作用就是去重复。请同学们仔细理解,多动手试验一下。

注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群













发表评论