



利用kaggle给的数据集,链接:https://www.kaggle.com/mczielinski/bitcoin-historical-data#coinbaseUSD_1-min_data_2014-12-01_to_2019-01-09.csv
Using the data set given by Kaggle & #xff0c; Links & #xff1a;
下载数据集后,解压,利用coinbaseUSD_1-min_data_2014-12-01_to_2019-01-09.csv文件
Download data sets xff0c; decompress xff0c; use coinbaseUSD_1-min_data_2014-12-01_to_2019-01-09.csv files
刚开始使用cpu跑的代码,CPU使用率为100%,内存也达到了15G,所以这次把代码改良了,采用GPU(GTX 1080Ti)跑,基本CPU32%,GPU12%,内存6G
The code for cpu running xff0c; CPU usage was 100% xff0c; memory also reached 15Gxff0c; so this time the code was improved xff0c; GPUxff08 was introduced; GTX 1080 Tixff09; Runff0c; Basic CPU 32% xff0c; GPU 12% xff0c; RAM 6G
比特币的价格数据是基于时间序列的,因此比特币的价格预测大多采用LSTM模型来实现。
长期短期记忆(LSTM)是一种特别适用于时间序列数据(或具有时间 / 空间 / 结构顺序的数据,例如电影、句子等)的深度学习模型,是预测加密货币的价格走向的理想模型。
Bitcoin price data are based on time series xff0c; therefore most Bitcoin price projections are made using the LSTM model.
Long-term short-term memory xff08; LSTM) a particularly time-series data xff08; or data with time/ space/ structure sequence xff0c; e.g. movies, sentences, etc. xff09; in-depth learning model xff0c; ideal model for predicting price trends for encrypted currencies.
在对应的conda环境中打开jupyter notebook,新建一个ipynb文件,然后输入下面代码。
Open jupyter notebook, in the corresponding conda environment; create a new ipynb file & #xff0c; then enter the following code.
数据加载
Load Data
查看原始数据
View raw data
在的数据一共有2099760条,数据由Timestamp、Open、High、Low、Close、Volume_(BTC)、Volume_(Currency)、Weighted_Price这几列组成。其中除去Timestamp列以外,其余的数据列都是float64数据类型。
There are 2099760 & #xff0c in total; the data are composed of Timestamp, Open, High, Low, Close, Volume_(BTC), Volume_Currenty, Weighted_Price. With the exception of Timestamp, xff0c; the remainder are float64 data types.
现在查看前10行数据
Now check the top 10 lines.
| Timestamp | Open | High | Low | Close | Volume_(BTC) | Volume_(Currency) | Weighted_Price | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1417411980 | 300.0 | 300.0 | 300.0 | 300.0 | 0.01 | 3.0 | 300.0 |
| 1 | 1417412040 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1417412100 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 1417412160 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 1417412220 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1417412280 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 6 | 1417412340 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7 | 1417412400 | 300.0 | 300.0 | 300.0 | 300.0 | 0.01 | 3.0 | 300.0 |
| 8 | 1417412460 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 9 | 1417412520 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
删除包含NaN值的任何行,把处理后的数据给data
| Timestamp | Open | High | Low | Close | Volume_(BTC) | Volume_(Currency) | Weighted_Price | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1417411980 | 300.00 | 300.0 | 300.00 | 300.0 | 0.010000 | 3.00000 | 300.000000 |
| 7 | 1417412400 | 300.00 | 300.0 | 300.00 | 300.0 | 0.010000 | 3.00000 | 300.000000 |
| 51 | 1417415040 | 370.00 | 370.0 | 370.00 | 370.0 | 0.010000 | 3.70000 | 370.000000 |
| 77 | 1417416600 | 370.00 | 370.0 | 370.00 | 370.0 | 0.026556 | 9.82555 | 370.000000 |
| 1436 | 1417498140 | 377.00 | 377.0 | 377.00 | 377.0 | 0.010000 | 3.77000 | 377.000000 |
| 1766 | 1417517940 | 377.75 | 378.0 | 377.75 | 378.0 | 4.000000 | 1511.93750 | 377.984375 |
| 1771 | 1417518240 | 378.00 | 378.0 | 378.00 | 378.0 | 4.900000 | 1852.20000 | 378.000000 |
| 1772 | 1417518300 | 378.00 | 378.0 | 378.00 | 378.0 | 5.200000 | 1965.60000 | 378.000000 |
| 2230 | 1417545780 | 378.00 | 378.0 | 378.00 | 378.0 | 0.100000 | 37.80000 | 378.000000 |
| 2245 | 1417546680 | 378.00 | 378.0 | 378.00 | 378.0 | 0.793600 | 299.98080 | 378.000000 |
先查看下数据是否含有nan的数据,可以看到我们的数据中没有nan的数据
Check if the data contains nan's data & #xff0c; you can see that we don't have nan's data.
可以看出现在已经没有NaN的数据了
As you can see, there's no data on Nan now.
再查看下0数据,可以看到我们的数据中含有0值,我们需要对0值做下处理
And look at 0 & #xff0c; we can see that our data contains 0 & #xff0c; we need to process 0 below.
处理0数据的方式是使用上个列值进行前向填充
Zero data is processed by using the previous column value for forward filling
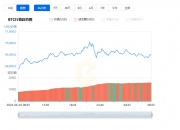
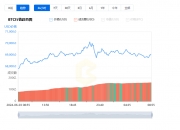
再看下数据的分布跟走势,这个时候曲线已经非常的连续
And look at the distribution of the data and the trend #xff0c; the curve is already very continuous at this time.


训练数据集和测试数据集划分
Training data sets and test data sets disaggregation
将数据归一化到0-1
Normalize data to 0-1
以2:8划分测试数据集跟训练数据集
Disaggregated test and training data sets by 2:8
创建训练数据集跟测试数据集,以1天作为窗口期来创建我们的训练数据集跟测试数据集。
Create training data sets and test data sets & #xff0c; create our training data sets and test data sets with a one-day window period.
loss为平均绝对误差(Mean Absolute Error,MAE)
loss is an average absolute error & #xff08; Mean Absolute Error, MAE)
这里节约时间,只训练20代,利用tensorflow-gpu=2.x,其中也有Keras,使用GPU训练,会更快
Time saving xff0c; training only 20 generations xff0c; using tensorlow-gpu#61; 2.x, with Keras, training xff0c using GPU; faster


预测
Projections


这只是作为数据分析的一个学习例子使用。
代码放在我的码云里,链接https://gitee.com/rengarwang/LSTM-forecast-price
This is only used as a learning example of data analysis.
code is placed in my code cloud xff0c; link
注册有任何问题请添加 微信:MVIP619 拉你进入群

打开微信扫一扫
添加客服
进入交流群












发表评论